E’ proprio il caso di scomodare l’intelligenza artificiale per riconoscere un cane da un mocio?
03/05/2019

Redazione
Categorie

Distinguere un cane da un mocio ai nostri occhi può risultare banale…ma se affidiamo questa operazione ad un computer non lo è affatto. Vedere per credere:

Un bravo sviluppatore può creare delle regole (il cane deve avere 4 zampe, 2 orecchie, etc…) affinché il riconoscimento visivo sia automatico, ma non possiamo mai essere sicuri che riuscirebbe a coprire tutte le casistiche? Molto probabilmente si troverebbe a rivedere le regole per tutta la sua vita…
Questo tipo di problemi è sempre stato affrontato con soluzioni molto specifiche, ma da qualche anno a questa parte è diventato la frontiera di un nuovo approccio, di cui tutti abbiamo certamente sentito parlare: l’intelligenza artificiale, tramite il suo fido scudiero, il machine learning.
L’intelligenza artificiale è l’abilità di simulare il comportamento umano ed i processi cognitivi che stanno alla base del funzionamento della nostra mente ossia: l’intelligenza, la percezione, il riconoscimento, la comprensione, ecc…
E’ quindi quello che rende un sistema capace di “pensare”, o perlomeno nel nostro immaginario è quello che ci fa dire “però! Intelligente!”
D’altro canto, per machine learning si intende un mezzo dell’intelligenza artificiale che raccoglie un insieme di metodi, sviluppati a partire dagli ultimi decenni del XX secolo in varie comunità scientifiche, sotto diversi nomi quali: statistica computazionale, riconoscimento di pattern, reti neurali artificiali, filtraggio adattivo, teoria dei sistemi dinamici, elaborazione delle immagini, data mining, algoritmi adattivi, ecc; che utilizza metodi statistici per migliorare progressivamente la performance di un algoritmo nell’identificare pattern nei dati.
Ok, perfetto… quindi cosa significa?
Il machine learning è l’apprendimento basato su esempi e sull’esperienza.
La macchina viene addestrata per mezzo di “esempi” (in gergo tecnico training set) affinché sia in grado di riconoscere una determinata immagine, un comportamento, un input vocale in completa autonomia.
E’ quindi la macchina stessa a scrivere le regole. Quali sono queste regole? Non è dato conoscere, possiamo solo misurare l’accuratezza delle risposte. Più “esempi” daremo al nostro computer più l’accuratezza aumenterà; ma attenzione: non bisogna che aumenti troppo, altrimenti diventerà troppo specializzato… se forniamo migliaia di immagini di auto di tre brand, ad esempio, potrebbe darsi che la nostra intelligenza (poco intelligentemente) riconosca come “auto” solo quelle di quei tre particolari brand. Ci vuole equilibrio!
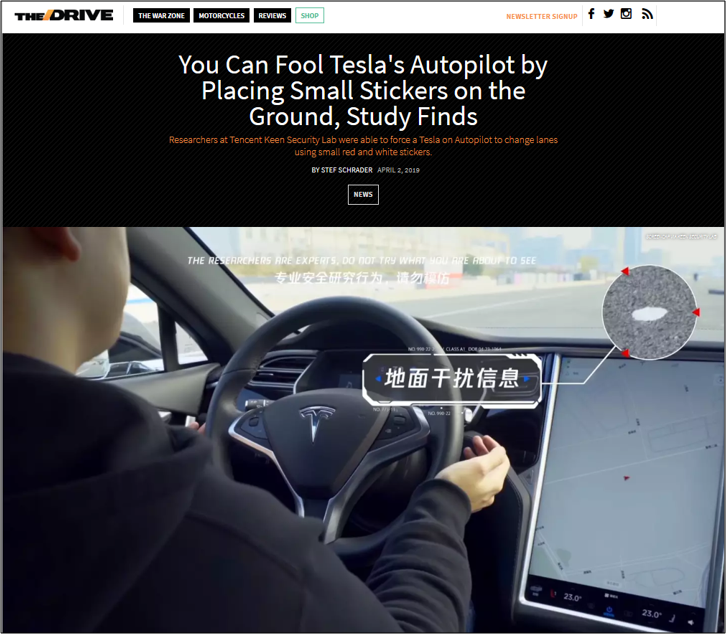
Non conoscere le regole in alcuni contesti può rappresentare un vero problema: emblematico il caso di Tesla. Chi sogna un giorno di avere un’auto con pilota automatico, sicuramente avrà seguito i diversi test drive del brand americano e avrà letto recentemente di come alcuni hacker cinesi abbiano trovato il modo di ingannare la Tesla Model S mettendo strategicamente alcuni semplici adesivi sulla strada. Conoscere le regole all’interno della “black box” Tesla, in questo caso, avrebbe decisamente aiutato a capire per tempo che per l’autopilota sono sufficienti tre quadratini applicati sulla strada per rilevare una corsia ed effettuare un cambio di direzione, mettendo così a rischio la sicurezza delle persone.
La soluzione? Cercare di capire, migliorare l’addestramento, riprovare con altre immagini… come potremmo fare per un animale da ammaestrare, insomma.
Fortunatamente in altri contesti non conoscere come la macchina ragiona non comporta delle implicazioni cosi disastrose. Anzi l’intelligenza artificiale può rappresentare un vero passo in avanti nell’ottimizzazione dei processi logistici di un’azienda come abbiamo visto al Logimat2019 (voice picking, tracciabilità oggetti e loro direzione per mezzo dell’RFID), oppure nell’aumentare le vendite creando nuovi bisogni o alimentando quelli latenti (se desideri approfondire l’argomento, leggi anche questo articolo sui recommender system) o ancora nel creare una customer experience avanzata rendendo possibile la prescriptive analytics.
Come capiamo quando è meglio utilizzare dei modelli già addestrati (ad esempio da Google, o da Amazon) e quando invece è meglio svilupparli in modo custom?
Nel caso dello speech to text ossia la funzione che converte la voce in testo, di cui abbiamo già parlato sia in ambito applicazioni di vendita sia voice picking, molto probabilmente ha senso sfruttare modelli già esistenti perché l’effort e l’investimento richiesto non giustificherebbe l’effettivo ritorno. Nel caso invece della gestione di un servizio come l’assistenza IT ai punti vendita da parte di un service desk risulta difficile attenersi ad una classificazione standard dei ticket, perché ogni azienda è diversa e in quanto tale necessita di categorie personalizzate. C’è spazio quindi per un valore aggiunto tutto nostro.
Certo, di I.A. si sente parlare ovunque, a volte anche a sproposito. E’ molto importante tenere sempre a mente che è uno strumento, non la soluzione; la sua applicazione non può prescindere dalla conoscenza diretta e approfondita dei meccanismi e del linguaggio propri del mio cliente e della mia applicazione… insomma, come nel caso di Tesla, sempre più in futuro senza I.A. non si andrà da nessuna parte, ma servirà sempre un pilota che sappia bene tenere gli occhi fissi sulla strada!











